Original Link: https://www.anandtech.com/show/2386
AMD's 3rd generation Opteron versus Intel's 45nm Xeon: a closer look
by Johan De Gelas on November 27, 2007 6:00 AM EST- Posted in
- IT Computing
Introduction
The new Xeon 45nm (or Xeon 54xx series) arrived in the lab weeks ago, so a server CPU benchmark update is overdue. However, there is another reason we decided to write this article. When AMD launched their newest quad-core chips, we could only give you a preview of its performance - not a full review. We did not fully understand many of the performance aspects of the new AMD architecture, so we decided to delve a little deeper.
We will only focus on performance in this article, as our primary goal is to get an idea where Barcelona (AMD's quad-core), Harpertown (Intel 45nm quad-core Xeon), and Clovertown (Intel quad-core 65nm Xeon) stand. To do so, we performed a minimal profiling of each of our benchmarks and we used several new micro benchmarks that will tell you a lot more than some real world benchmarks can. If you like understanding the benchmarks out there a bit better, dig in.
The new 45 Xeon
The new 45nm Xeon 54xx series, aka "Harpertown", is still based on the Core architecture, but it has been tweaked a bit. We have already discussed those improvements in detail here and here, so we won't discuss them in detail again, but here's a quick overview:
- Faster 4-bit divider (Radix-16) instead
of 2-bit divider
- Up to 1600MHz FSB
- Shared 6MB (24-way set associative) instead 4MB L2 cache (per dual-core
die)
- Super Shuffle engine (For SSE instructions)
- Split Load Cache Enhancement
- SSE4
The Radix 16 divider is the most interesting of these improvements. Dividing involves a repetition of subtractions, tests "if-it-fits" and shifts. If you can do this with four bits at a time instead of two, this means that you can cut the number of these iterations required to get your result in half. The square root calculation is similar and also benefits from these improvements. While divisions and square roots are rather rare in common software, they have a very significant performance impact. Contrary to the more "popular" instructions, they are not pipelined and the latency of these instructions is high. For example, a floating-point multiply takes five cycles and the "Clovertown Core" architecture can finish one every two cycles thanks to pipelining. However, a floating-point division takes no less than 32 cycles and cannot be pipelined at all.

Nanotechnology is here: a core with 820 million transistors and you can fit at least two of them in one coin. (Photo by Tjerk Ameel)
Besides being an improved "Clovertown", the new Xeon is also a marvel of nanotechnology with no less than 410 million transistors on a die of only 107 mm². Two die make one quad-core Xeon 54xx. Considering that this CPU is close to behemoth CPUs like Itanium and Power 6 in SPECint performance, the new Intel is a formidable adversary for AMD's newest quad-core.
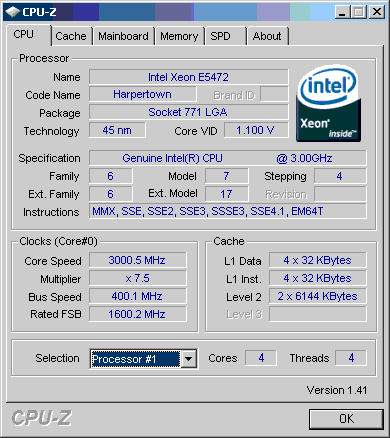
There is more than the CPU of course. The new CPU works on the old "Bensley/5000P chipset" platform, though we were not able to get it running on our P5000PSL Intel motherboard despite the fact that we applied the BIOS update that came out early this month.
There is also a new HPC/workstation platform for the Intel Xeon thanks to the Seaburg chipset, which features an improved snoop filter. Besides reducing the snoop traffic, the new chipset should also be able to extract more bandwidth out of the same FBDIMMs. The support for DDR2-800 FBDIMMs should bring another performance boost but our current test platform is only stable with DDR2-667 FBDIMMs.
The Opteron 2360SE - the Facts
Getting back to AMD, the new quad-core chip still lives under veil of secrecy. Quite a few rumors and myths are going around and we investigated them one by one so we could be sure that you only get the facts.
Fact 1: The B2 stepping does not have a much faster memory controller than the B1 stepping
The controller found in stepping "2" might be a tiny bit faster, but we have not found any significant difference. Our Stream benchmarks were only a tiny bit faster on the 2.5GHz (Stepping 2) than on the 2GHz (Stepping DR-B1) and so were the latency numbers.
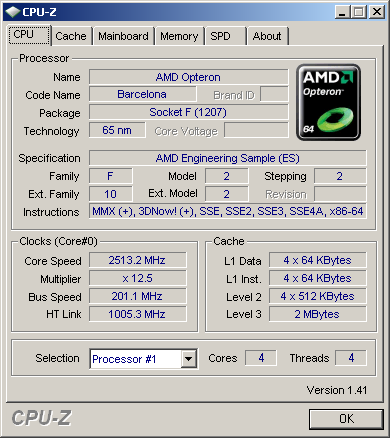
The 2.5GHz Barcelona is a newer stepping than the 2GHz sample we tested earlier.
Fact 2: The 2.5GHz review sample is running at 1.2V; it is not overclocked
CPU-Z reported that the chip was running at 1.5V, while the 2GHz quad-core was running at 1.2V.
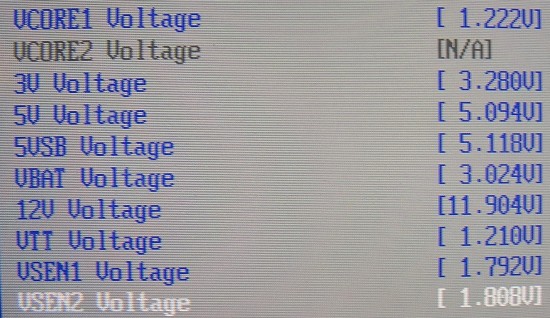
Power measurements show that the BIOS of our ASUS board is accurate, but CPU-Z is not. The last evidence is of course the laser marking on the quad-core Opteron.

AMD is capable of producing 2.5GHz quad-core, but not in large quantities at this time. The 2.5GHz part should arrive at the end of this year, with large quantities expected in the first quarter of 2008.
Fact 3: the memory controller always runs RAM at the rated frequency
In this case, the new quad-core Opteron is completely different from what we have seen with previous Opteron (and Athlon 64) processors. In the first and second generation Opteron, the memory controller ran at a divisor of the CPU. This resulted in very odd memory clocks speeds at times, particularly on odd multipliers. For example, a 2.2GHz Opteron (11X multiplier) uses a divisor of 7 and ends up running DDR2-667 (333.5MHz clock) at 314MHz. That gives DDR2-628 instead of 667. In reality, this doesn't have any major performance impact, and it is only measurable with "Stream-like" benchmarks. In contrast, Barcelona's memory controller runs at its own frequency and will run the DIMMs at the rated speed.
Fact 4: By running the Northbridge at a lower speed, the new quad-core loses a bit of performance but saves power
The core of the Opteron 2360 runs at 2.5GHz, but the L3 cache runs at Northbridge frequency, which is 2GHz. It seems that AMD's engineers felt that running the L3 at core frequency would not have resulted in significantly higher performance, but significantly higher power dissipation. From another point of view, given a certain power envelope, running the Northbridge and the L3 cache at higher frequencies would result in lower core frequencies.
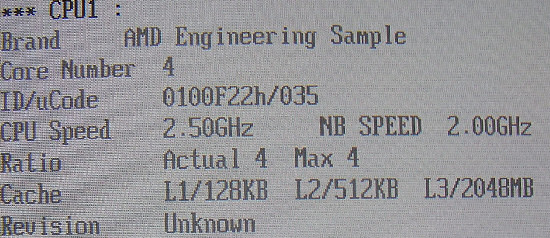
Fact 5: The L3 cache was a good choice, but…
The L3 cache does increase latency of accessing the main memory but decreases the average latency seen by the CPU. This leads to the question of whether the relatively slow L3 cache is really an advantage. The L3 cache has a latency of 43 cycles (2GHz) or 48 cycles (2.5GHz), but it's still quite a bit faster than system memory, which takes about 130 to 170 cycles to access.
In addition, it has one main advantage for server workloads. If more than one core is accessing a cacheline in the L3 cache, it will remain in the L3. If not, the L3 cache will behave like a fully exclusive cache: it will send the cacheline to the L1 and throw out the cacheline to make place for a "victim" of the L2. This allows relatively fast sharing of data between threads, which is important for large code footprint applications like database applications and others. For single-threaded applications, it looks like they get a 2.5MB L2 cache, although with an average latency of about 20 cycles.
Still, there is no doubt that the L3 cache of Barcelona could have been a bit bigger to score even better in the larger database benchmarks such as TPC. We have to guess that a larger L3 cache became a victim (pun intended) of the already large 283 mm² die size. Still, a 44 cycle latency (and more) is rather disappointing for only 2MB of L3 cache.
Fact 6: Dual-Link is possible with AMD 2xxx Opterons
Several readers asked us how it was possible that our ASUS KFSN4-DRE board linked our 2350 CPUs with two instead of one HyperTransport point-to-point connection, as the 23xx Opteron supports only one coherent HyperTransport link. However, the constraint is not the number of links but actually the number of coherent responses that are supported. Our ASUS board does feature twice as much bandwidth for CPU-to-CPU traffic (snoop, access to remote memory etc.)
Words of Thanks
Many people gave us assistance with this project, and we would of course like to thank them.
Trevor Lawless, Intel US
Sanjay Sharma, Intel US
Matty Bakkeren, Intel Netherlands
(www.intel.com)
Damon Muzny, AMD US
Joshua Mora, AMD US
Brett Jacobs, AMD US
(www.amd.com)
Randy Chang, ASUS
(www.asus.com)
Kelly Sasso, Crucial Technology
Benchmark configuration
Here is the list of the different configurations. We flashed all servers to the latest BIOS, and unless we add any specific comments to the contrary, the BIOS are set to default settings.
Xeon Server
1: Intel "Stoakley platform" server
Supermicro X7DWE+/X7DWN+ Bios rev 1.0
2x Xeon E5472 at 3GHz
8GB (4x2GB) Crucial Registered FB-DIMM DDR2-667 CL5 ECC
NIC: Dual Intel PRO/1000 Server NIC
Xeon
Server 2: Intel "Bensley platform" server
2x Xeon E5365 at 3GHz or 2x Xeon E5345 at 2.33GHz
Intel Server Board S5000PSL - Intel 5000P Chipset
8GB (4x2GB) Crucial Registered FB-DIMM DDR2-667 CL5 ECC
NIC: Dual Intel PRO/1000 Server NIC
Opteron 2350 Server: ASUS KFSN4-DRE
Dual Opteron 2350 2GHz
Asus KFSN4DRE BIOS version 1001.02 (8/28/2007) - NVIDIA nForce Pro 2200 chipset
8GB (4x2GB) Crucial Registered DDR2-667 CL5 ECC
NIC: Broadcom BCM5721
Opteron Socket F 1207 Server: Tyan Transport
TA26 - 2932
Dual Opteron 2222 3GHz/2224SE 3.2GHz
Tyan Thunder n3600m (S2932) - NVIDIA nForce Pro 3600 chipset
8GB (4x2GB) Crucial Registered DDR2-667 CL5 ECC
NIC: nForce Pro 3600 integrated MAC with Marvell 88E1121 Gigabit Ethernet PHY
Client Configuration: Dual Opteron 850
MSI K8T Master1-FAR
4x512MB Infineon PC2700 Registered, ECC
NIC: Broadcom 5705
OS Software
64-bit SUSE Linux SLES 10 SP1 (Linux 2.6.16.46-smp x86_64)
32-bit Windows 2003 Enterprise SP1
The memory subsystem (Linux 64-bit)
Most of the applications of the server and HPC world are well multi-threaded and scale nicely with more cores. With the exception of some rendering engines, this also means that our hard working quad-core CPUs will require quite a bit more bandwidth when they are processing these multi-threaded applications. In our previous review, we found out that:
- Barcelona's L2 cache is 50 to 60% faster
than the older Opteron (22xx). So each core gets at least 50% more L2 bandwidth.
- Each Barcelona's L2 cache is almost as fast as the
shared L2 cache of a similarly clocked 65nm Core based Xeon.
The Intel Xeon has a big advantage of course: its L2 cache is 8 to 12 times larger!
- Barcelona's single-threaded memory bandwidth is 26% to 50% better than the older Opteron and almost twice as good as what a similar Intel Xeon gets.
The problem is of course the word "single-threaded". Those bandwidth numbers are not telling us what we really want to know: how well does the memory subsystem keep up if all cores are processing several heavy threads?
We only had access to the Intel and GCC compilers, and we felt we should use a different compiler to create our multi-threaded stream binary. GCC would probably not create the fastest binary and Intel's compiler might give the Core architecture too many software prefetch hints (or other tricks that might artificially boost the bandwidth numbers). Alf Birger Rustad helped us out and sent us a multi-threaded, 64-bit Linux Stream binary based on v2.4 of Pathscale's C-compiler. We used the following compiler switches:
-Ofast -lm -static -mp
We tested with one, two, and four threads. "Two CPUs" means that we tested with four threads on dual dual-core and eight threads on dual quad-core. "2 CPUs" also means that we used only one CPU in the 1-4 threads setting and we only used a second CPU in the "2 CPUs" setup.
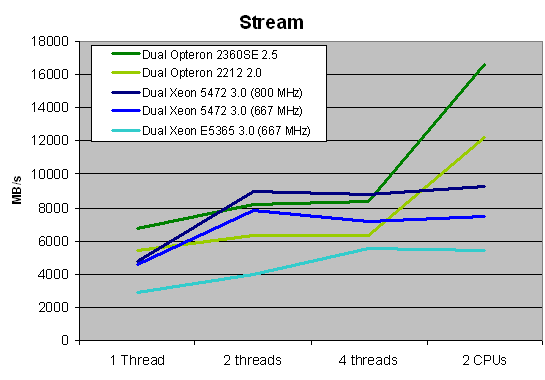
Note that clock speeds do not really matter, except for the Socket-F Opteron. Although we did not include this in the graph above (to avoid color chaos), the clock speed of the socket-F Opteron only matters for the single-threaded bandwidth numbers. Look at the table below:
| AMD vs. AMD Multi-threaded Stream | |||
| 1 Thread | 2 threads | 2 CPUs | |
| Dual Opteron 2212 2.0 | 5474 | 6330 | 12220 |
| Dual Opteron 2222 3.0 | 6336 | 6472 | 12664 |
| Difference 3GHz vs. 2GHz | 16% | 2% | 4% |
| Dual Opteron 23xx | 6710 | 8232 | 16614 |
| Difference Opteron 23xx vs. Opteron 22xx | 23% | 30% | 36% |
With one thread, the 2GHz Opteron 2212 is clearly not fast enough to take advantage of the bandwidth that DDR2-667 can deliver. However, once you make both cores work, this is no longer the case. The Opteron 23xx numbers make clear that the deeper buffers really help: each quad-core has about 30% more bandwidth available than the dual-core. That should be more than enough to keep twice as many cores happy.
The graph above also quantifies the platform superiority that many ascribe to AMD. Likewise, it confirms that the new Intel platform has a much better memory subsystem thanks to the Seaburg chipset. To understand this we calculated the bandwidth numbers, with the "Bensley + Clovertown" platform representing our baseline 100%.
| AMD vs. Intel Multi-threaded Stream | ||||
| 1 Thread | 2 threads | 4 threads | 2 CPUs | |
| Opteron 23xx | 232% | 207% | 150% | 308% |
| Xeon 54xx + Seaburg + 800MHz RAM | 164% | 225% | 158% | 172% |
| Xeon 54xx + Seaburg + 667MHz RAM | 159% | 196% | 128% | 138% |
If you use two CPUs, the Opteron 23xx has no less than 3 times the amount of bandwidth compared to the "old" 65nm Xeon. However, it is much less likely that bandwidth will be a bottleneck for the "new" Xeon 45nm as it has 40% to 60% more bandwidth (with the same kind of memory) compared to the "old" Xeon. If necessary, you'll be able to use 800MHz FBDIMMs that will offer more bandwidth (9GB/s versus 7.7GB/s).
It becomes clear why even a 3GHz Xeon 5365 is not able to beat AMD in SPECFP2006rate: running eight instances of SPECFP2006 is bandwidth limited.
The memory subsystem, latency
To understand the memory subsystem of the different CPUs, we also need to look at latency. We have noticed that many latency measurement benchmarks are inaccurate when you have two CPUs running, so we tested with only one socket filled. Below you can see the numbers for a stride of 128 Bytes, measured with the CPU-Z 1.41 latency test.
| CPU-Z Memory Latency | |||||
| Data size (kB) | Opteron 2212 2.0 | Opteron 2350 | Opteron 2360SE | Dual Xeon
5472 (DDR2-667) |
Xeon E5365 |
| 4 | 3 | 3 | 3 | 3 | 3 |
| 8 | 3 | 3 | 3 | 3 | 3 |
| 16 | 3 | 3 | 3 | 3 | 3 |
| 32 | 3 | 3 | 3 | 3 | 3 |
| 64 | 3 | 3 | 3 | 15 | 14 |
| 128 | 12 | 15 | 15 | 15 | 14 |
| 256 | 12 | 15 | 15 | 15 | 14 |
| 512 | 12 | 15 | 15 | 15 | 14 |
| 1024 | 12 | 44 | 48 | 15 | 14 |
| 2048 | 114 | 44 | 48 | 15 | 14 |
| 4096 | 117 | 111 | 121 | 15 | 14 |
| 8192 | 117 | 113 | 126 | 242 | 215 |
| 16384 | 117 | 113 | 125 | 344 | 282 |
| 32768 | 117 | 113 | 126 | 344 | 282 |
The quad-core Opteron had to make a compromise or two. As the 463 million transistor chip is already 285 mm² in size, each core only gets a 512 KB L2 cache. That means that in some situations (>512 KB) the old 90nm Opteron 22xx is better off as it has access to a very fast 12 cycle L2 cache while the Opteron 23xx has to access a rather slow 44-48 cycle L3 cache.
Note also that the 2.5GHz Opteron 2360 "sees" a slower L3 cache than the 2350: 48 cycles versus 44. The memory controller seems to be ok: the slightly higher latency compared to the Opteron 22xx series is a result of the fact that the Opteron 23xx cores have to check the L3 cache tags, while the Opteron 22xx doesn't have to do that. Notice that memory latency of the on-die memory controller is still far better (+/- 60 ns) than what the Seaburg or Blackford chipset (+/- 70-90 ns) can offer to the Xeon Cores. We have encountered situations where Barcelona's memory controller accesses the memory with much higher latencies (86 ns and more) than the Opteron 22xx but we have to study this in more detail to understand whether this has a realworld impact or not.
Native quad-core versus dual dual-core, part 2
Cache2Cache measures the propagation time from a store by one processor to a load by the other processor. The results that we publish are approximately twice the propagation time.
We noticed that running our Cache2Cache benchmark (see here and here) gives results that are more accurate if you measure the results on the same die with only one CPU, and then measure the results from one CPU die to another one with two CPUs. Cache2cache quantifies the delay that a "snooping" CPU encounters when it tries to get up-to-date data from another CPU's cache.
| Cache coherency ping-pong (ns) | |||
| Same die, same package |
Different die, same package |
Different die, different socket |
|
| Opteron 2350 - Stepping B1 | 127 | N/A | 199 |
| Opteron 2360SE - Stepping B2 | 107 | N/A | 199 |
| Xeon E5472 3.0 | 53 | 150 | 237 |
| Xeon E5365 3.0 | 53 | 150 | 237 |
The Xeon syncs very quickly via its shared L2 cache (26.5 ns), but a bit slower from the first CPU to the third one (75 ns). AMD's native quad-core design is a bit faster in the latter case (53.5 ns with the 2360 SE). The difference is slightly less when you have to sync between two sockets (99.5 ns versus 118.5).
Floating-point Analyses (Linux 64-bit)
AMD's newest quad-core behaves pretty weird when it comes to floating-point applications. In some FP intensive applications (CINEBENCH and LINPACK for example) a 2GHz quad-core cannot even keep up with Intel's older 2GHz 65nm quad-core CPUs; in other applications it is a close match (3ds Max, POV-Ray); finally, in applications like zVisuel's 3D Engine and SPECfp, Barcelona is clearly faster clock-for-clock than the older generation. Our aim is to understand this situation a little better and to see what the 45nm Xeon 54xx can achieve.
To understand this we first tested with two synthetic, but completely opposite FP benchmarks:
- LINPACK,
which calculates on massive matrices
- FLOPS, which fits in an 8 KB L1 cache
Let us start with LINPACK. LINPACK, a benchmark application based on the LINPACK TPP code, has become the industry standard benchmark for HPC. It solves large systems of linear equations by using a high performance matrix kernel.
We used a workload of square matrices of sizes 5000 to 30000 by steps of 5000, and we ran four (dual dual-core) or eight (dual quad-core) threads. As the system was equipped with 8GB of RAM, the large matrixes all ran in memory. LINPACK is expressed in GFLOPS (Giga/Billions of Floating Operations Per Second).
We used two versions of LINPACK:
- Intel's
version of LINPACK compiled with the Intel Math Kernel Library (MKL)
- A fully optimized "K10-only" version for AMD's quad-core
The "K10-only" version uses the ACML version 4.0.0, compiled using the PGI 7.0.7. We used the following flags:
pgcc -O3 -fast -tp=barcelona-64
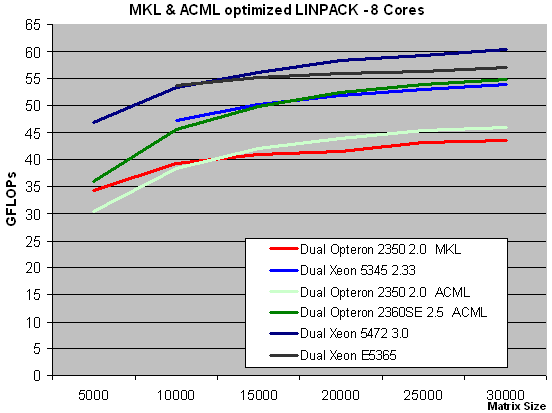
The graph above may come as a surprise to a quite few people. At the lower matrix sizes, AMD's quad-core is even a bit faster with the "Intel version" than with the specially optimized version. Only while calculating with the larger matrices does the heavily tuned version pull ahead. The K10-only version of LINPACK is about 6% faster, and the most important reason for that improvement is the ACML library of AMD. However, it is clear that the Intel MKL and compiler are not slowing the AMD core down when it is running LINPACK.
There is more. At first sight, the AMD 2360SE scores seem rather poor: just a tiny bit faster than the 2.33GHz quad-core of Intel. However, the Intel CPU scales rather poorly with clock speed: a 3GHz Clovertown is only 6% faster than a 2.33GHz one while the clock speed advantage is 28%. The Barcelona core however scales 19% from a 20% clock speed boost. The new Seaburg platform cannot help here: a 3GHz Xeon E5365 was capable of 57.1 GFLOPS, while it got 57 GFLOPS with the older chipset.
Intel's clever compiler engineers have already found a way around this, as the newest release of their LINPACK version is quite a bit faster on both Clovertown and Harpertown. The LINPACK score increases to 70 GLOPs for the Xeon 5472 3GHz (60.5 in our test) and 63 for the Xeon E5365 3GHz (57 in our test). Unfortunately, we don't have any data on what has changed, so we decided to freeze our benchmark code for now.
Raw FPU power: FLOPS
Let us see if we understand floating-point performance better when we look at FLOPS. FLOPS was programmed by Al Aburto and is a very floating-point intensive benchmark. Analysis show that this benchmark contains:
- 70% floating-point
instructions
- Only 4% branches
- Only 34% of instructions are memory instructions
Benchmarking with FLOPS is not real world, but isolates the FPU power. Al Aburto states the following about FLOPS:
"Flops.c is a 'C' program which attempts to estimate your systems floating-point 'MFLOPS' rating for the FADD, FSUB, FMUL, and FDIV operations based on specific 'instruction mixes'. The program provides an estimate of PEAK MFLOPS performance by making maximal use of register variables with minimal interaction with main memory. The execution loops are all small so that they will fit in any cache."
FLOPS shows the maximum double precision power that the core has, by making sure that the program fits in the L1 cache. FLOPS consists of eight tests, and each test has a different but well-known instruction mix. The most frequently used instructions are FADD (addition, 1st number), FSUB (subtraction, 2nd number), and FMUL (multiplication, 3rd number). FDIV is the fourth number in the mix. We focused on four tests (1, 3, 4, and 8) as the other tests were very similar.
We compiled three versions:
- Gcc
(GCC) 4.1.2 20070115 (prerelease) (SUSE Linux)
- Intel C Compiler (ICC) version 10.1 20070913:
- An x87 version
- A fully vectorized SSE2 version
- An x87 version
Let us restate what we are measuring with FLOPS:
- Single-threaded
double precision floating performance
- Maximum performance not constrained by bandwidth bottlenecks or latency delays
- Perfect clock speed scaling
This allows us to calculate the FLOPS per cycle number: we divide the MFLOPs numbers reported by FLOPS by the clock speed. This way we get a good idea of the raw floating-point power of each architecture. First we test with the basic '-O3' optimization.
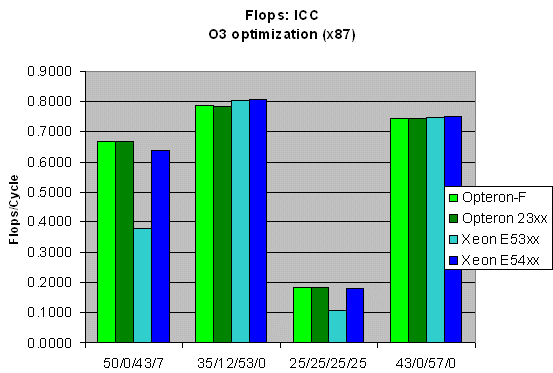
Don't you love the little FLOPS benchmark? It is far from a real world benchmark, but it tells us so much.
To understand this better, know that the raw speed of the AMD out of order x87 FPU (Athlon K7 and Athlon 64) used to be between 20% and 60% faster clock for clock than any P6 based CPU, including Banias and Dothan. However, this x87 FPU advantage has evaporated since the introduction of the Core architecture as the Core Architecture has a separate FMUL and FADD pipe. (Older P6 architectures could execute one FADD followed by one FMUL, or two FP operations per two clocks at the most). You can see that when we test with a mix of FADD/FSUB and FMUL, the Core architecture is slightly faster clock for clock.
The only weakness remaining in the Core x87 architecture is the FP divider. Notice how even a relatively low percentage of divisions (the 4th number in the mix) kills the performance of our 65nm Xeon. The Opteron 22xx and 23xx are 70% faster (sometimes more) when it comes to double precision FP divisions. However, the new Xeon 54xx closes this gap completely thanks to lowering the latency of a 64-bit FDIV from 32 cycles (Xeon 53xx) to 20 cycles (Xeon 54xx, Opteron 23xx). The Xeon 54xx is only 1% to 5% slower in the scenarios where quite a few divisions happen. That is because the Opterons are capable of somewhat pipelining FDIVs, which allows them to retire one FDIV every 17 cycles. The clock speed advantage of the 45nm Xeon (3.2GHz vs. 2.5GHz maximum at present) will give it a solid lead in x87 performance.
However, x87 performance is not as important as it used to be. Most modern FP applications make good use of the SSE SIMD instruction set. Let us see what happens if we "vectorize" our small FLOPS loops. Remember, FLOPS runs from the L1 cache, so L2 and memory bandwidth do not matter at all.
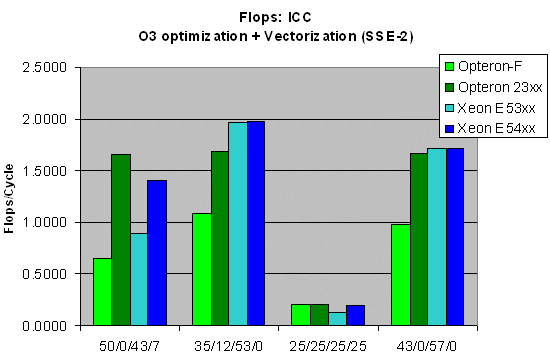
When it comes to raw SSE performance, the Intel architectures are 3% to 14% faster in the add/subtract/multiply scenarios. When there are divisions involved, Barcelona absolutely annihilates the 65nm Core architecture with up to 80% better SSE performance, clock for clock. It even manages to outperform the newest 45nm Xeon, but only by 8% to 18%. Notice once again the vast improvement from the 2nd generation Opteron to the 3rd generation Opteron when it comes to SIMD performance, ranging from 55% to 150% (!!).
As not all applications are compiled using Intel's high-performance compiler, we also compiled with the popular open source compiler gcc. Optimization beyond "-O3" had little effect on our FLOPS binary, so we limited our testing to one binary.
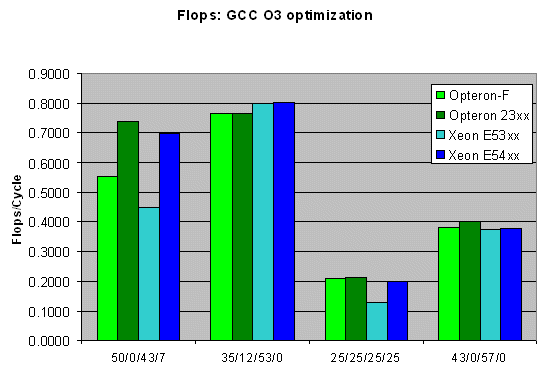
GCC paints about the same picture as ICC without vectorization. The new AMD Barcelona core has a small advantage, as it is the fastest chip in 3 out of 4 tests. Let us now see if we can apply our FP analyses of LINPACK and FLOPS to real world applications.
3ds Max 9 (32-bit Windows)
We tested with the 32-bit version of 3ds Max version 9, which has improvements that help multi-core systems but which is not as aggressively tuned for SSE as LINPACK and zVisuel. We used the "architecture" scene, which has been a favorite benchmarking scene for years. We performed all tests with 3ds Max's default scanline renderer, we enabled SSE support, and we rendered at HD 720p (1280x720) resolution. We measured the time it takes to render ten frames (frames 20 to 29).
As promised, we profiled our different benchmarks to understand them better. We performed profiling with AMD's CodeAnalyst; VTune profiling will follow later. 3ds Max runs four modules when you render:
- Render
(46% of the time)
- Ray-FX (28%)
- Geometry (15%)
- Core (11%)
To keep things simple, we summarized our findings with a weighted average over all modules.
| 3dsmax Profiling | |
| Profile | Total |
| Average IPC (on AMD 2350) | 1 |
| Instruction mix | |
| Floating Point | 39% |
| SSE | 12% |
| Branches | 13% |
| L1 datacache ratio | 0.56 |
| L1 Instruction ratio | 0.27 |
| Performance indicators on Opteron 2350 | |
| Branch misprediction | 6% |
| L1 datacache miss | 1% |
| L1 Instruction cache miss | 5% |
| L2 cache miss | 0% |
As you can see, 3ds Max is mostly about floating-point performance with a bit of SSE instructions. It runs perfectly in the L1 and L2 cache of our CPUs. To make the graph easier to read we did not report our results in the classic way (rendering time) but expressed them in images rendered per hour (10 images * 3600 seconds divided by render time). Higher is therefore better.
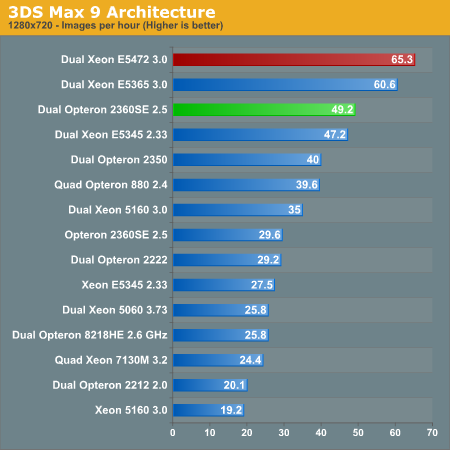
The Xeon 5472 is about 8% faster than its older brother and widens the gap from the AMD Armada. We included quite a few results of older tests. This benchmark focuses on the CPU; chipset and RAM choices don't impact performance much. Interestingly, the Opteron 2350 is about as fast as four 2.4GHz single-core Opterons. Thus, in software with a "small dash" of SSE, the new architecture is about 20% faster. If we extrapolate our AMD quad-core results to 3GHz, the result would be about 59 images per second, which indicates that AMD's newest is about 10% slower than Intel clock for clock. That is no real surprise anymore: FLOPS showed us that the raw x87 FP and SSE power of AMD's latest architecture is slightly lower than the newest Xeon. It also can only overpower the Xeon 53xx if there are enough divisions involved. AMD's Barcelona architecture will only show a real advantage in bandwidth limited FP situations such as SPECfp2006 and many HPC applications.
Software Rendering: zVisuel (32-bit Windows)
This benchmark is the zVisuel Kribi 3D test, which is exclusive to AnandTech.com and which simulates the assembly of a mechanical watch. The complete model is very detailed with around 300,000 polygons and a lot of texture, bump, and reflection maps. We render more than 1000 frames and report the average FPS (frames per second). All this is rendered on the "Kribi 3D" engine, an ultra-powerful real-time software rendering 3D engine. That all this happens at reasonable speeds is a result of the fact that the newest AMD and Intel architectures contain four cores and can perform up to eight 32-bit FP operations per clock cycle and per core. The people of zVisuel told us that - in reality - the current Core architecture can sustain six FP operations in well-optimized loops. Profiling for Barcelona architecture is not yet complete, so we did our best with CodeAnalyst 2.74 for Windows. We only profiled the non-AA benchmark so far.
| ZVisuel Kribi3D Profiling | |
| Profile | Total |
| Average IPC (on Opteron 2350) | 1 |
| Instruction mix | |
| Floating Point | 31% |
| SSE | 35% |
| Branches | 6% |
| L1 datacache ratio | 0.63 |
| L1 Instruction ratio | 0.22 |
| Performance indicators on Opteron 2350 | |
| Branch misprediction | 8% |
| L1 datacache miss | 1% |
| L1 Instruction cache miss | 1% |
| L2 cache miss | 0% |
This is a very different engine than the scanline-rendering engine of 3ds Max. SSE instructions play a very dominant role, and the zVisuel Kribi 3D benchmark gives us a view on how the different CPUs perform on well-optimized SSE applications. While the application seems to run almost perfectly from the L2 cache, this seems to be a result of well-tuned, predictable access to the memory. We noticed that hardware prefetching and the new Seaburg chips help this benchmark a lot:
| Zvisuel Intel Platform Performance Comparison | |||
| CPU | HW Prefetch on | HW Prefetch disabled | Difference |
| Dual Xeon E5365 3.0 (Blackford) | 99.9 | 87.7 | 14% |
| Dual Xeon E5365 3.0 (Seaburg) | 110 | 104.2 | 6% |
| Dual Xeon E5472 3.0 (Seaburg) | 124.8 | 110 | 13% |
Let us see all the results.
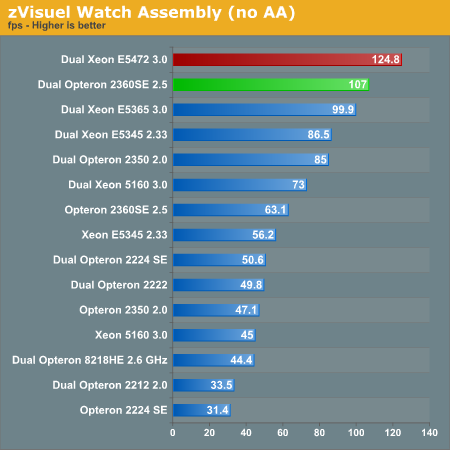

Although we haven't done a detailed analysis, we can assume that the "Super Shuffle Engine" and "Radix-16" divider that Intel has implemented in the Xeon 5472 is paying off here. AMD Opteron 2360 SE at 2.5GHz can overtake the best Xeon at 65nm, but the new Xeon has a tangible lead. A silver lining to the cloud hanging over AMD is that the Opteron 23xx series scale perfectly with clock speeds: compare the 2GHz with the 2.5GHz results. Still, Intel has the advantage when it comes to SSE processing.
The results with AA show that the memory subsystem of the Xeon 53xx is a major bottleneck, but the new Seaburg chipset has made this bottleneck a bit smaller. The result is a crushing victory for the latest Intel architecture. Enough FP testing, let us see what Barcelona can do when running typical integer server workloads.
64-bit Linux Java Performance: SPECjbb2005
If you are not familiar with SPECJbb2005, please read our introduction to it here. SPECjbb2005 from SPEC (Standard Performance Evaluation Corporation) evaluates the performance of server side Java by emulating a three-tier client/server system with emphasis on the middle tier.
We tested with two JVMs:
- SUN Java HotSpot(TM) 64-Bit Server
VM (build 1.6.0_02-b05, mixed mode)
- BEA JRockit(R) (build R27.4.0-90 linux-x86_64, compiled mode)
We used the following optimizations:
- Sun JVM: -Xms2g -Xmx2g -Xmn1g -Xss128K
-XX:+AggressiveOpts -XX:+UseParallelOldGC -XX:+UseParallelGC
- BEA JVM: -Xms1800m -Xmx1800m -Xns1500m -XXaggressive -XXlazyunlocking -Xgc:genpar -XXtlasize:min=4k,preferred=512k -XXcallprofiling
The BEA JVM uses memory more aggressively, making more use of the assigned memory. A heap size of 2GB would probably result in the JVM gobbling up too much memory, which could result in errors or poor performance on our 8GB system. That is why we lowered the JVM heap size from 2G to 1.8 G. We also applied slightly more aggressive tuning to the BEA JVM, as their customers are more interested in squeezing out the last bit of performance.
We also used four JVMs per system. The reason is that most IT departments emphasize consolidation today, and it is very rare that one JVM gets eight cores. We fully disclosed our testing methods here. However, note that you cannot compare the results below with our previous findings as we use newer JVMs now.
Below you can find the final score reported by SPECjbb2005, which is an average of the last four runs.
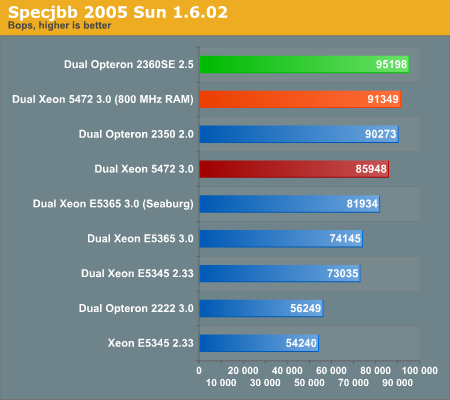
It took us hours, but we managed to complete one run of SPECjbb with faster 800MHz DDR. It shows with four JVMs that the memory subsystem on the Xeon systems is a clear bottleneck. It is also important to note that SPECjbb is one of the most sensitive benchmarks to memory bandwidth. If SPECjbb improves 6% when we use 800MHz ram instead of 667MHz, this is probably about the maximum boost the new Xeon will get from slightly faster 800MHz memory.
Let us see how the systems fare with the BEA JRockit JVM.

BEA uses some clever compression techniques to alleviate the pressure on the memory system. However, it is a bit funny to see how the hardware prefetching gets in the way. While it boosted performance by 14% in our zVisuel Kribi 3D, it is now slowing down the SPECjbb benchmark by 14%. When we disable it, the Xeon 5472 takes the lead.
The Xeon 3GHz looks like a sports car with his wheels deeply entrenched in the mud: the raw power keeps spinning on the lack of memory bandwidth. A 3GHz chip is hardly faster than a 2.33GHz chip, and here AMD's quad-core at 2GHz beats Xeon.
64-bit MySQL (Linux 64-bit)
MySQL has released version 5.1.22, which supposedly can scale up to eight CPU cores. That would be a huge improvement considering that all versions earlier than 5.0.37 could only make good use of two CPU cores. In our experience, this new binary scales well up to four cores, but eight cores are easily 20% slower than four core systems. Thus, we tested with a maximum of four cores.
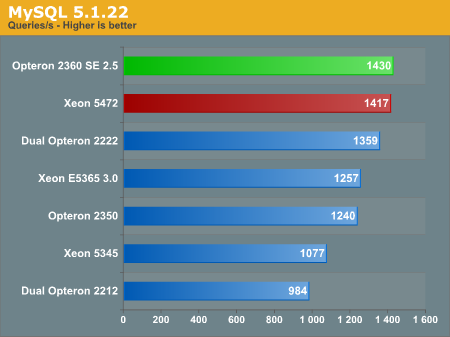
Please note that these results cannot be compared with our earlier MySQL results. MySQL v5.1.22 is a completely different binary than v5.0.2x we tested previously. Although it still doesn't scale beyond four cores, it is up to 70% (!!) faster than v5.0.26 that came standard with our SLES 10 SP1. For smaller servers with four cores, MySQL is once again an ultra fast database.
Moreover, the third generation of Opterons absolutely loves this new MySQL version. At 2.5GHz, it is just as fast (the margin of error is up to 4%) as the mighty Xeon 5472 at 3GHz. As we failed to profile MySQL in depth (CodeAnalyst for Linux still has some quirks), we cannot pinpoint the exact reason why the Opteron 23xx is so good at this. The MySQL database is mostly limited by synchronizing the locks, so we suspect that the slightly faster cache coherency syncing on the Opteron 23xx might be one of the reasons AMD's latest performs so well.
WinRAR 3.62 (Windows 32-bit)
WinRAR 3.62 is a completely different kind of workload.
| WinRAR 3.62 Profiling | |
| Profile | Total |
| Average IPC (on AMD 2350) | 0.36 |
| Instruction mix | |
| Floating Point | 0% |
| SSE | 0% |
| Branches | 9% |
| L1 datacache ratio | 1.13 |
| L1 I cache ratio | 0.35 |
| Performance indicators (on Opteron 2350) | |
| Branch misprediction | 7% |
| L1 datacache miss | 4% |
| L1 Instruction cache miss | 0% |
| L2 cache miss | 3% |
Notice that contrary to the other workloads we have profiled so far, WinRAR does not run perfectly in the L1 or L2 cache. Second, notice the huge amount of loads that happen: more than one per retired instruction.

The massive bandwidth that Barcelona can offer multi-threaded software pays off here. You can also see that the Seaburg chipset improves the score of the 3GHz quad-core Xeon by 7%.
Fritz Chess Benchmark (Windows 32-bit)
WinRAR and Fritz Chess are probably less important to most people than the other benchmarks we ran. However, the reason why we include them in this article is that their profile is so different from the other applications. In this way, we get more insight into the different new architectures.
| Fritz Chess | |
| Profile | Total |
| Average IPC (on AMD 2350) | 0.99 |
| Instruction mix | |
| Floating Point | 4% |
| SSE | 0% |
| Branches | 17% |
| Performance indicators on Opteron 2350 | |
| Branch misprediction | 12% |
| L1 datacache ratio | 0.65 |
| L1 Instruction ratio | 0.37 |
| L1 datacache miss | 1% |
| L1 Instruction cache miss | 1% |
| L2 cache miss | 0% |
We have said this before but it warrants repeating: you'll find a decent amount of complex branches in a chess program. 17% branches is not that extraordinary, but the fact that 12% of those branches are mispredicted is. If we compare a 2GHz Opteron 22xx with an Opteron 23xx, we should see if the improvements in branch prediction pay off.

The Opteron 2350 is about 3% faster than the Opteron 22xx, core for core, clock for clock. We believe we can assume that the branch prediction improvements are minor, as the Fritz chess benchmark runs in the L1 and L2 cache.
HPC
Several of the HPC benchmarks are too expensive for us to test, but we can get some information from AMD's and Intel's own benchmarking. According to Intel, the new Intel Xeon 5472 (1.89 score) is about 26% faster than the Xeon 5365 (1.5 score) when running the fluent benchmark. According to AMD, the Opteron 2350 is about 10% to 60% faster than a 2.33GHz Xeon E5345. That doesn't give us much comparison data, but at first sight it seems that AMD will be competitive in Fluent even at lower clock speeds (2.5GHz versus 3GHz).
We get a little more data in LS-DYNA. Both AMD and Intel have published results.
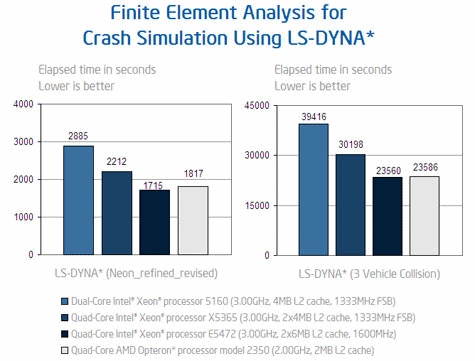
Intel's own marketing material seems to admit that a Xeon E5472 with 800MHz memory is just as a fast as AMD's quad-core at 2GHz. AMD's 2.5GHz model will surely take the lead in LS-DYNA. Looking at the Fluent and LS-DYNA benchmarks it appears that AMD will remain very competitive in the HPC market.
One benchmark where Intel's newest chip really shines is the Black-Scholes algorithm: as most of the calculations involve divisions, the new Xeon 54xx chips are about 50% faster than their older Xeon 53xx siblings, clock for clock. Unfortunately, our compilation of Black-Scholes failed on the quad-core AMD, so we have to postpone those results for now.
Conclusion
When it comes to floating-point performance, we feel we can say we have a very good picture of what AMD's and Intel's best are capable off. The Barcelona floating-point architecture is able to beat the 53xx in quite a few benchmarks, but the Xeon 5472 shows that AMD's third generation Opteron is late to the party. Our FLOPS, LINPACK, and rendering benchmarks show that the Xeon 5472 is at least as good as or better than AMD's latest in raw FP performance on a clock-for-clock basis.
We have less data on "pure" integer performance, with the exception of our Fritz Chess benchmark. This benchmark gave us a first hint that the improvement in integer performance from the Opteron 22xx to the Opteron 23xx is probably rather small. The single-threaded SpecInt2006 numbers published by IBM are probably not optimal, but also confirm this:
- A 1.9GHz Opteron 2347 got a score of
11.3, 9.97 base
- A 2GHz Opteron 2212 gets a score of 10.8, 9.77 base
- A 2GHz Xeon E5335 gets a score of 15.5, 14 base
This indicates that the Opteron 23xx is about 10% faster in integer tasks than the 22xx series. Considering that the best SPECint_rate2006 score of AMD's quad-core at 2.5GHz is 102 while Intel's 5460 (3.16GHz) is already at 138, we think it is safe to assume that the integer performance of AMD's Barcelona is still not up to Intel Core levels. The Xeon 5365 at 3GHz is also able to deliver a significantly higher score (117). This, together with our own benchmark data, makes us believe that the Xeon 54xx based on the Penryn architecture will beat the best AMD chips on every aspect of raw processing performance: integer, legacy x87 FP, and SIMD (SSE). It is clear now why Intel's CPUs are so dominant in desktop and workstation workloads.
Add to this a significant clock advantage: there is already a 3.2GHz Xeon 5485 (150W). If you prefer a less power hungry CPU, Intel can provide a 3GHz 5472 that is still clocked 20% higher than what AMD will be able to deliver 2 to 3 months later. Although the 3GHz models are quite pricey (>$1000), you can already find a 2.5GHz quad-core Xeon for $316. That's the same price as a 1.9GHz Opteron 2347 chip. There is little doubt in our mind that a 2.5GHz Xeon is faster in almost every application we can think off, so Intel's newest Xeon does have the price/performance crown as well.
While AMD loses quite a few battles, the war is far from lost. The server/HPC situation is entirely different from the desktop scene where the Core 2 Quad overpowers the Phenom in almost every benchmark. There is more to server and HPC performance than simple raw processing power. Intel's flagship still has an Achilles heel: the platform it is running on has higher latency and much lower bandwidth than AMD's platform. Once you really stress all those cores with many threads, AMD's platform starts to pay off.
Look at the summary of our benchmarking below. (Blue numbers mean Intel is faster; green show a victory for the AMD chip).
| AMD vs. Intel Performance Summary | ||
| General applications | Opteron 2360SE vs. Xeon E5365 |
Opteron 2360SE vs. Xeon 5472 |
| WinRAR 3.62 | 23% faster | 6% faster |
| Fritz Chess engine | 24% slower | 26% slower |
| HPC applications | ||
| LINPACK | 4% slower* | 9% slower* |
| 3D Applications | ||
| 3DS Max 9 | 19% slower | 25 % slower |
| zVisuel 3D Kribi Engine | 7% faster | 14% slower |
| zVisuel 3D Kribi Engine (AA) | 2% slower | 23% slower |
| Server applications | ||
| SPECjbb (Sun) | 28% faster | 11% faster |
| SPECjbb (BEA) | 12% faster | 12% slower |
| MySQL | 14% faster | Equal |
* Faster LINPACK binaries from Intel were available at the time that we finished this article.
To put it in car terms, our SPECjbb, LINPACK, and MySQL benchmarks have shown that Intel's "powerful CPU engines" sometimes have problems putting the "massive torque" to the "wheels". You may feel for example that using four instances in our SPECjbb test favors AMD too much, but there is no denying that using more virtual machines on fewer physical servers is what is happening in the real world. Intel's best have a solid lead over AMD's quad-core in rendering benchmarks, but some HPC, Java and MySQL benchmarks show that the 2.5GHz Barcelona is able to keep up with (or come close to) a 3GHz Xeon 5472. That is impressive, on the condition that we finally see some higher clocked Opteron 23xx chips in commercially available servers.
We still cannot draw any solid conclusion on the server performance of AMD's quad-core as no MS Exchange, SAP ERP, TPC-C, or TPC-H results have been published. In fact, with the exception of the SPECjbb and MySQL numbers in this article, all server benchmarks on AMD's third generation Opteron are MIA. This situation will probably continue for a few more months as most of these benchmark results traditionally come from OEMs and not AMD.






